5.1.3 Acoustic Modeling: Hidden Markov Models

|
Hidden Markov Models are based on the idea of a Markov Chain, which describes
a sequence of random variables, X,Y, and Z each conditionally dependent
only on the previous, thus forming a "chain". It can be informally defined
as follows:
P(X,Y,Z) = P(X)P(Y|X)P(Z|Y)
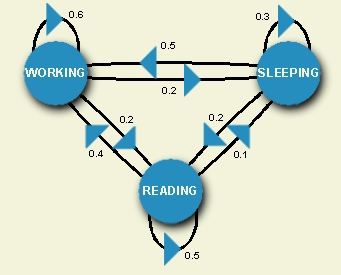
The Markov Chain uses direct observations of the behaviors of the
random variables or states. For example, we can let X, Y, and
Z represent three states: working, sleeping, and reading. We can
observe a speech researcher in these three states over many days and
compute the probability that he or she is in a particular state or
transitioning to another state at any given instance. For example,
the probability that this researcher transitions from working to
sleeping at a given time is 0.2.
|
The diagram to the right can be viewed as a
finite state machine
which gives the probabilities of transitioning from a given state
at a particular time, based on direct knowledge of the state sequences.
A hidden Markov Model adds a predictive component to the Markov chain,
outputting probabilities of transitioning to a particular state at the
next instance in time.
The term hidden is used because it outputs these probabilities
when the original state sequence is not known.
This predictive power makes it well-suited for modeling stochastic
(random) events and processes in which we must determine behavior
that cannot be directly known. This is especially important for
speech recognition, where the words a person speaks are not
known but must be determined by how closely
they match a model of the measurements of they should sound.
HMM's can be used to build such a model to provide the likelihood
of a sequence of states. In speech recognition, the states comprise
feature vectors; thus
the HMM's yield the likehood of a particular sequence of acoustic vectors.
See
Section 3
for description of feature vectors.
|
|
|







