5.1.4 Acoustic Modeling: Acoustic Model Types

The predictive power of HMM's enables them to form the basis of
a machine or model that can learn the characteristics of a
class of random data. This learning takes place by exposing
the model to sufficient examples of the data where
the values are known. Such a model, if trained properly,
can predict the data values when
they are not known, as must be done for speech recognition.
To initialize and train such a model for speech recognition,
we record numerous samples of people speaking various words
and phrases.
We then label the words and phrases of these samples, thus creating
"training" data from which the model can learn. We show
the model each of these training samples in controlled
sequences, allowing it to
"learn" by
reestimating
its output probabilities according to
what is known from the labeled data, thus yielding P(A|W).
The acoustic unit modeled in training can be either a word or a phoneme.
Both of these acoustic model types are explained in detail in
Section 4.2
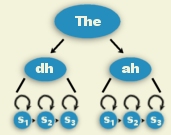
Word models
include each of the phonemes produced for
an entire word. The model for the word "the" is shown to the right.
Word models are generally used for recognition experiments consisting of
few possible words. For example, word models can effectively be used
for TI Digits recognition experiments. They are not very effective for
experiments consisting of large vocablulary speech. For large vocabulary,
phone models are more practical.
Phone models
contain the smallest acoustic components of a language. For example,
the English language consists of about 46 phones. The image to the
right shows the phones that make up one pronounciation of the word
"the". Each of these acoustic model types have a specific training
process associated with them.
The next several sections of this tutorial explain how to initialize and
train acoustic
models for speech recognition using our software. First, the process of
training word models will be explained, followed by the process of
training context independent phone models. Next, context dependent
model training will be discussed. This tutorial includes examples for
training both word internal context dependent models and cross-word
context dependent models. The last section of this tutorial will
explain parallel training.
|
|
|







