5.1.2 Acoustic Modeling: Statistical Methods

As discussed in
Section 5.1.1,
a speech
recognizer must determine what words and phrases are spoken, by
comparing the measurements of how they sound when spoken to the
measurements contained in the acoustic models.
This determination is inherently probabalistic due to the
variability in the way human speech sounds. This variability depends
on the speaker and the environment in which the sound is produced.
Therefore, we can view speech recognition as solving the problem of
finding:
P(W|A)
where P is the probability that a particular word W
was spoken given what is known about how a particular word is supposed
to sound, i.e., the
measurements of its acoustics A .
From
Bayes' Rule,
we know that we can solve this problem using the
following equation:
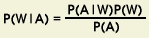
P(A|W) is the probability of the acoustic
measurements A given the word W is known.
This represents the acoustic model.
P(W) is the independent probability that a word
W occurred.
The language model, discussed in
Section 6,
provides this information.
P(A) is the probability of the acoustic
measurements A.
In this section, we focus on the development of the acoustic models,
represented by P(A|W). Fundamental to this development is a
statistical technique known as the
Hidden Markov Model (HMM).
Simply stated, HMM's yield the statistical
likelihood of a particular pattern, e.g., a sequence of words or phonemes.
They are used in both training to determine P(A|W) and recognition to
determine P(W|A). Continue to
Section 5.1.3
for further description of HMM's.
|
|







