|
5.2.5 Word Models: Mixture Splitting The algorithms for reestimation are not guaranteed to converge to a globally optimal solution. They may converge only to a locally optimal solution. In order to come closer to a globally optimal solution, the models need to be perturbed between iterations. Although not guaranteed in every case, model perturbation can often be accomplished by mixture splitting. It can also be shown that, given sufficient data to estimate the model parameters, a Gaussian mixture can model any statistical distribution. However, overfitting the training data can be a problem. Overfitting is a phenomenom that occurs when too many models are used and the network has too much freedom in fitting a surface to the training data. The training data will be well fitted, but the surface generalizes poorly for the test data. In the image below, the graph on the left has been generalized with the black line that makes a good approximation for the training and the test data, but the graph on the right has been overfitted, resulting in a poor generalization for the test data. Cross-validation can be used to counter this problem. 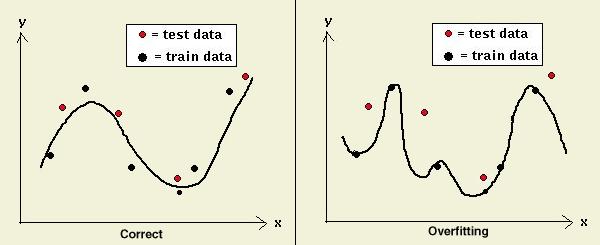
2 Mixtures Go to the directory:
Now, train the mixures with 4 passes of Baum Welch using this command:
Command: isip_recognize -parameter_file params_2mix_train.sof -verbose brief -list $ISIP_TUTORIA./databases/lists/identifiers_train.sof Version: 1.23 (not released) 2003/05/21 23:10:45 loading audio database: $ISIP_TUTORIA./databases/db/tidigits_audio_db.sof *** no symbol graph database file was specified *** loading transcription database: $ISIP_TUTORIA./databases/db/tidigits_trans_word_db.sof loading front-end: $ISIP_TUTORIAL/recipes/frontend.sof loading language model: $ISIP_TUTORIAL/models/lm_word_digraph_2mix_split.sof loading statistical model pool: $ISIP_TUTORIAL/models/smp_word_2mix_split.sof loading configuration file: $ISIP_TUTORIAL/sections/s05/s05_02_p04/config.sof starting iteration: 0 processing file 1 (ae_12a): $ISIP_TUTORIA./databases/sof_8k/train/ae_12a.sof retrieving annotation graph for identifier: ae_12a, level: word transcription: ONE TWO average utterance probability: -71.112650988296565, number of frames: 110 processing file 2 (ae_1a): $ISIP_TUTORIA./databases/sof_8k/train/ae_1a.sof retrieving annotation graph for identifier: ae_1a, level: word transcription: ONE average utterance probability: -68.104989807008536, number of frames: 87 ....Increasing the number of mixtures reduces the error rate. Sixteen mixtures typically yields satisfactory results. In this tutorial we will split up to eight mixtures. Follow the instructions below to continue splitting mixtures. 4 Mixtures Run the following command to split the mixtures:
Command: isip_recognize -parameter_file params_4mix_train.sof -verbose brief -list $ISIP_TUTORIA./databases/lists/identifiers_train.sof
Version: 1.23 (not released) 2003/05/21 23:10:45
loading audio database: $ISIP_TUTORIA./databases/db/tidigits_audio_db.sof
*** no symbol graph database file was specified ***
loading transcription database: $ISIP_TUTORIA./databases/db/tidigits_trans_word_db.sof
loading front-end: $ISIP_TUTORIAL/recipes/frontend.sof
loading language model: $ISIP_TUTORIAL/models/lm_word_digraph_4mix_split.sof
loading statistical model pool: $ISIP_TUTORIAL/models/smp_word_4mix_split.sof
loading configuration file: $ISIP_TUTORIAL/sections/s05/s05_02_p04/config.sof
starting iteration: 0
processing file 1 (ae_12a): $ISIP_TUTORIA./databases/sof_8k/train/ae_12a.sof
retrieving annotation graph for identifier: ae_12a, level: word
transcription: ONE TWO
average utterance probability: -71.112650988296565, number of frames: 110
processing file 2 (ae_1a): $ISIP_TUTORIA./databases/sof_8k/train/ae_1a.sof
retrieving annotation graph for identifier: ae_1a, level: word
transcription: ONE
average utterance probability: -68.104989807008536, number of frames: 87
processing file 3 (ae_2789385a): $ISIP_TUTORIA./databases/sof_8k/train/ae_2789385a.sof
....
8 Mixtures
Run the following command to split the mixtures:
Command: isip_recognize -parameter_file params_8mix_train.sof -verbose brief -list $ISIP_TUTORIA./databases/lists/identifiers_train.sof
Version: 1.23 (not released) 2003/05/21 23:10:45
loading audio database: $ISIP_TUTORIA./databases/db/tidigits_audio_db.sof
*** no symbol graph database file was specified ***
loading transcription database: $ISIP_TUTORIA./databases/db/tidigits_trans_word_db.sof
loading front-end: $ISIP_TUTORIAL/recipes/frontend.sof
loading language model: $ISIP_TUTORIAL/models/lm_word_digraph_8mix_split.sof
loading statistical model pool: $ISIP_TUTORIAL/models/smp_word_8mix_split.sof
loading configuration file: $ISIP_TUTORIAL/sections/s05/s05_02_p04/config.sof
starting iteration: 0
processing file 1 (ae_12a): $ISIP_TUTORIA./databases/sof_8k/train/ae_12a.sof
retrieving annotation graph for identifier: ae_12a, level: word
transcription: ONE TWO
average utterance probability: -71.364267500334037, number of frames: 110
processing file 2 (ae_1a): $ISIP_TUTORIA./databases/sof_8k/train/ae_1a.sof
retrieving annotation graph for identifier: ae_1a, level: word
transcription: ONE
average utterance probability: -68.266543983088013, number of frames: 87
processing file 3 (ae_2789385a): $ISIP_TUTORIA./databases/sof_8k/train/ae_2789385a.sof
....
|







