5.2.4 Word Models: Multi-Path Silence Training

|
In the previous step, silence was automatically added at the beggining
and end of each utterance transcription and the models were trained.
Now, we want to train the models further, but account for the silence
between each word in the utterance. We call this process multi-path
silence training. This word-internal silence is sometimes (but not
always) shorter than the silence at the beginning and ending of an
utterance, so we want to use an acoustic unit that better models these
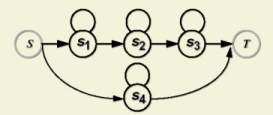
short pauses. The figure to the right illustrates the accoustic model
used for word-internal silence. States 1, 2, and 3 model long durations
of silence, while state 4 models short durations.
Once again, the recognizer automatically
inserts the silence between each word in an utterance transcriptions.
This saves us from having include silence symbols in out transcription
database and also saves us the trouble of using different transcriptions
for the single and multi-path silence training steps.
|
|
The parameter file for this step is slightly different than the one we
used for single-path silence training. Go to the directory:
$ISIP_TUTORIAL/sections/s05/s05_02_p04/
and look at the parameter file,
params_sp.sof.
You'll notice that most of the parameters are the same, but that a
configuration parameter has been added. This parameter
points to a configuration file in the same directory called
config.sof.
This configuration file contains yet another parameter called
search_non_speech_internal_symbols that is assigned the
SILENCE symbol. This parameter tells the recognizer to add the
SILENCE symbol to the language model as a non-speech internal
symbol, or more specifically, a symbol that the recognizer
will assume exists between two words in an utterance.
From this directory, run the command:
isip_recognize -param params_sp.sof -list $ISIP_TUTORIA./databases/lists/identifiers_train.sof -verbose brief
Expected Output:
loading audio database: $ISIP_TUTORIA./databases/db/tidigits_audio_db.sof
*** no symbol graph database file was specified ***
loading transcription database: $ISIP_TUTORIA./databases/db/tidigits_trans_wo\
rd_db.sof
loading front-end: $ISIP_TUTORIAL/recipes/frontend.sof
loading language model: $ISIP_TUTORIAL/models/word_models/lm_word_jsgf_init.s\
of
loading statistical model pool: $ISIP_TUTORIAL/models/word_models/smp_word_in\
it.sof
*** no configuration file was specified ***
starting iteration: 0
processing file 1 (ae_12a): $ISIP_TUTORIA./databases/sof_8k/train/ae_12a.sof
retrieving annotation graph for identifier: ae_12a, level: word
transcription: ONE TWO
average utterance probability: -82.462353512546912, number of frames: 110
processing file 2 (ae_1a): $ISIP_TUTORIA./databases/sof_8k/train/ae_1a.sof
retrieving annotation graph for identifier: ae_1a, level: word
transcription: ONE
...
This step completes the silence training process. Next, we'll explore
a training technique that can be used to improve our models called
mixture splitting.
|







