|
The network trainer provides the ability to directly reestimate multi-path models within the Baum-Welch paradigm. Having the ability to directly reestimate multi-path models however comes at the expense of efficiency. This tutorial describes the techniques that are being employed to improve the efficiency of the network trainer. The overall goal is to bring the network trainer close to the same level of performance as a traditional HMM trainer without any loss of generality or flexibility. As with most algorithms a speedup can be achieved if some of the work can be done ahead of time (pre-processing). The network trainer is no different in that a speedup in the reestimation process can be achieved by pre-processing the transcription. The next two sections will describe why pre-processing the transcription is necessary in order to improve the efficiency of the reestimation process. Dynamic Transcription Expansion The network trainer is built upon a hierarchical engine. This means that each level of the transcription is expanded dynamically. The figure below describes how the words in the transcription are expanded all the way down to the hidden Markov model (HMM) states. 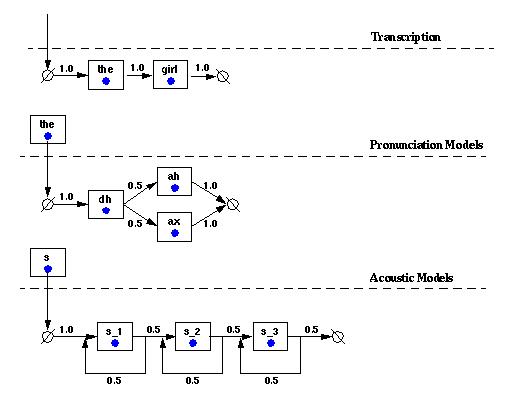
The time taken to dynamically expand the transcription down to the HMM states can be reduced by using a static network. A static network is similar in many respects to the network shown above. The main difference being interconnects that are created to join the various levels of the hierarchy. The interconnects coalesce the different levels in the hierarchy into a single traversable network. A static network resembles a traditional HMM trainer in that all the data structures needed for reestimation can be allocated ahead of time. In a traditional HMM trainer, phonetic transcriptions are employed during reestimation. The phonetic transcriptions allow us to concatenate a group of HMM states (corresponding to the phones in the transcription) and use them during reestimation. This saves a lot of overhead because we don't have to deal with pronunciation networks, which, are necessary when using orthographic transcriptions during reestimation. Context Dependency When dealing with context independent symbols the static network described above would suffice, however, context dependent symbols require a lookahead mechanism. The lookahead mechanism searches for all possible right contexts for a given symbol in the hierarchy. For example, in the network shown above the symbol /dh/ has two possible right symbols /ah/ and /ax/. The lookahead mechanism will generate two context dependent symbols for the context independent symbol /dh/, i.e., it will generate the symbols /dh+ax/ and /dh+ah/. Naturally, the efficiency of the reestimation process, for context dependent symbols, can be improved if we moved the lookahead to the pre-processing stage. The figure below describes how adding contextual information to the static network can speedup the reestimation. 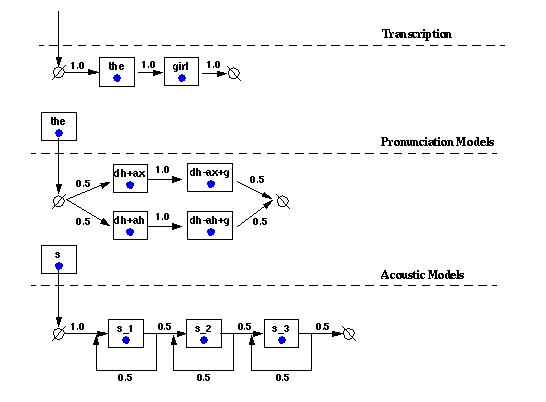
The pre-processing stage, expands the static network to include all context dependency information. Because the context expansion is done in the pre-processing stage we save a lot of time and effort during reestimation. The context expanded network reduces the overhead of searching for all possible right symbols every time we encounter a context independent symbol. |