|
We recently released our r00_n10 version of our speech recognition toolkit. This release contains many common features found in modern speech to text (STT) systems: a front end that converts the signal to a sequence of feature vectors, an HMM-based acoustic model trainer, and a time-synchronous hierarchical Viterbi decoder. The new features over last release include:
Phonetic Decision Trees Most state-of-the-art Large Vocabulary Conversational Speech Recognition (LVCSR) systems use context-dependent Hidden Markov Models (HMMs) to model speech data. In order to model the variations in speaker characteristics and pronunciations, it is common for an LVCSR system to use several million parameters, which need to be estimated using several hours of speech training data. This explosion in the number of parameters is primarily because of the need to model acoustic units in terms of their context. However, many acoustic contexts are not observed with sufficient frequency in the training data, and therefore estimating model parameters for each context-dependent acoustic unit is difficult. Using discrete or semi-continuous density HMMs, or continuous density HMMs with tied parameters can significantly reduce the total number of model parameters to be estimated. A phonetic decision tree-based module for phonetic state tying is now integrated in the ISIP STT toolkit. This algorithm uses both the training data as well as phonetically derived questions to cluster the states. It is also capable of handling models with contexts that rarely occur in the training data, if at all. The implementation of this algorithm is based on the Maximum Likelihood (ME) principle, where the trees are grown till a significant increase in likelihood can be achieved. The likelihood computation is based on state occupancy counts produced during HMM training. The current implementation uses occupancy counts based on the Viterbi estimation algorithm. The state tying module has two operating modes:
The lexical tree-based N-gram decoding is implemented based on a generalized hiearchical search space [1]. The basic idea of lexical tree expansion is to collapse pronunciation models of different words by sharing the same beginning phonemes. The use of a lexical tree significantly reduces the search space and search effort. Based on the idea of sharing the common prefix, we extend the prefix tree representation to any level in the search hierarchy. Our implementation of lexical tree-based decoding enables users to set the decoder to expand a lexical tree at any level. If a user sets the decoder to use lexical tree decoding at level i, the symbols of the level i will be expand to their corresponding sub-graphs at level i+1 and the common prefix of these symbols will be shared, resulting in a tree-structured search. Lexical tree based decoding is implemented especially for context-dependent phone models, where the search space grows significantly without the lexical tree-based decoder. Context-dependent phone models, defined as a model which depends on preceding and following sounds, are generally more accurate than context-independent phone models, since the former can capture coarticulatory effects. In our implementation, the concept of a context-dependent model can be used at any level. If a symbol S is context-dependent then the underlying model is determined dynamically via its neighboring symbols. This generalized implementation imposes no restrictions on the length of context and the number of levels using context. Similarly, N-gram models are extended to N-symbol models. The symbol can be a phrase, a word or a phone, depending on the level at which it is used. The decoder does not restrict the order of the N-symbol model. Therefore, users can apply arbitrarily long time-span language or acoustic models to meet the needs of their applications. The user interfaces for lexical tree-based N-gram decoding include:
The annotation graph [2] represents the linguistic annotation of recorded speech data. The linguistic annotation, in the case of speech recognition, is simply an orthographic annotation of speech data, which may or may not be time-aligned to an audio recording. The orthographic annotation, generally referred to as a transcription, is a label associated with the audio recording. The transcription along with the audio recording is used to train the speech recognition system in a supervised learning framework. The annotated transcription may include a hierarchy of linguistic, syntactic and semantic knowledge sources that needs to be conveniently represented. The annotation graph provides a convenient means for representing a hierarchy of knowledge sources. An annotation graph may be used to represent a single transcription or an entire conversation depending on how the speech database is organized. This alleviates the problem of having multiple copies of the same transcription for each knowledge source, and it also provides an application programmer interface (API) to tag and query the various knowledge sources. The following is an example of how to build an annotation graph that contains the orthographic transcription "the" and its corresponding phones /dh/ and /ax/: 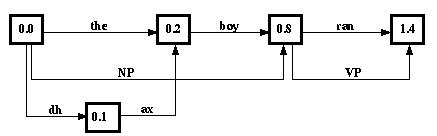
The annotation graph representation is integrated into our speech recognition system in both training and decoding.The user interfaces for annotation graph include:
Included in this release is a script that guides users through all the steps required to develop a speech recognition system. The experiment in this tutorial is a continuous digit recognition task based on TIDigits. The recognition system is our standard HMM system based on context-dependent cross-word phonetic models and MFCC features. This tutorial is self-paced. All the files required for this experiment have been bundled with this package. All files and executables in this experiment are assumed to be relative to the $ISIP_TUTORIAL environment variable. In order to run the tutorial you will need to so the following:
$ISIP_TUTORIAL/scripts/tutorial.sh Conclusion This release represents a substantial enhancement to our r00_n09 release. This release delivers most of the functionality expected in a state of the art system, and duplicates most of the functionality in our popular prototype system. We expect the interfaces included in this system will be stable, and will be supported in future releases. The next release of this system, which will primarily deal with efficiency issues, will be r01_n00. References
|