|
5.6.1 Parallel Training: Overview Training is a very computationally intensive process, with several millions of computations to be made for a typical set of data. For a large set of training data, consisting of several hundred hours of speech, training on a single processor can take months to complete. Parallel training addresses this problem by splitting the task of training across multiple processors. This can greatly decrease the time it takes to process a set of training data. To train a HMM from M data sequences (utterances), we must maximize the joint likelihood: 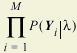
During the training process, both the state-transition and the state-observation probability distributions are updated at the end of each pass. However, the update equations for both of these probability distributions can be nicely decomposed to allow for parallel training on N processors. For example, the partial update for the state-transition can be defined as 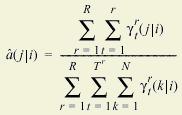
This second equation demonstrates how parallel training is possible. We can run (R/N) files on N processors and accumulate the sums inside the first summation. Once each processor has finished computing its own piece of the data, the output is combined and the final estimates of the new parameters are made. Working in this way, a task that would take T amount of time on one processor would take T/N + C where N is the number of processors and C is the amount of time required for retrieving the data from N disks and combining the results. |







