In this tutorial, I will explain a novel capability of the
production system that allows multiple utterances per file to be
processed. This is very useful since it can significantly reduce
processing time. Some databases, such as SWITCHBOARD, consist of
long conversations, often 5 to 10 minutes in duration. In the
past, we have segmented such long data into short utterances
typically 5 to 10 secs in length, and then processed these
individual files. We call this a one utterance per file format.
This format is inefficient for standard computer processing
because the operating system will spend more time opening and
closing the file than it will spend processing the data in the
file. As computers have increased in speed, processing times are
often 0.1 xRT (0.1 secs per one second of speech data). The total
time it takes to process 500 hours of data in a one utterance per
file format is often limited by the I/O time - particularly the
time it takes for the disk to seek the data, open the file, etc.
To overcome this, we have developed a facility in which a single
file can contain multiple utterances. Hence, a conversation need
not be separated into lots of small files. The utterance segmentation
and transcription information is provided to the recognizer in the
form of a
transcription database
that contains both the start and stop times of each utterance
as well as the corresponding transcription for that segment.
This database is described in much more detail in our
online speech recognition tutorial.
1. An Overview of the Speech Recognition Process
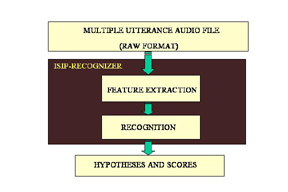
A basic block diagram of the speech recognition process is shown
to the right. There are two main processes involved in decoding
of a speech file:
- Feature Extraction:
Only certain attributes or features of a person's speech are
helpful for decoding sound units, called phones. These features
are extracted using a combination of spectral and temporal
measurements. See
feature extraction
for more information on how to convert an audio file to
a feature file.
- Recognition:
The process of finding the most probable set of symbols,
typically words, for an utterance is known as recognition
(or decoding). For more information on recognition, see
recognition.
|
|
2. Multiple Utterances Per File
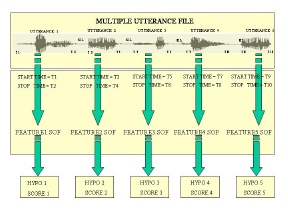
A file containing multiple utterances is shown to the right. As
mentioned above, some data, such as recordings of telephone
conversations, naturally lends itself to such a file organization.
Other data can be put in this format to speed up processing time
by decreasing I/O wait times. The features are calculated
separately for each utterance using the timing information in the
transcription database. The recognizer can read sampled audio data
or feature files in this multiple utterance per file format.
|
|
3. Experimental Setup:
Below, we lead you through a simple example of how to execute
an experiment using this capability. The main components are:
- Audio File: A file with multiple utterances.
- Audio Database: This database manages a set of audio
files using a simple database indexing scheme in which each
file is identified by a key (referred to as an audio
id). To learn more about audio database and how to create
one, see our
online tutorial.
- Transcription Database: This database manages the
transcriptions for each file. It plays a key role in feature
extraction of multiple utterance since it has the timing
information (start and stop times) for each utterance.
To learn more about transcription database and how to create one,
see our
online tutorial.
- Acoustic Models: These are used by the recognizer
to perform statistical modeling of the input signal.
To learn more about acoustic models, see our
online tutorial.
- Language Models: While the acoustic models built from
the extracted features enable the recognizer to decode phonemes
that comprise words, the language models specify the order in
which the sequence of words is likely to occur. To learn more
about language models, see our
online tutorial.
- Recipe Files: A recipe is a single entity that stores
information about how we convert a speech signal into a
sequences of vectors in a signal flow graph. To learn how to
create a recipe, see our
online tutorial.
All of this information is encapsulated in a parameter file.
To learn more about configuration of the recognizer,
I would recommend you follow several exercises
available in our
online tutorial.
Here are some sample commands that can be used to execute the
steps described above:
- To create an audio and transcription database:
isip_make_db -db both -audio audio_list.text
-trans trans_list.text -level \
word -name TIDigits -type text audio_db.sof trans_db.sof
- To run recognition:
isip_recognize -parameter_file params/params_decode.sof \
-list lists/identifiers.sof
In the future, we plan to release more experimental setups that
make use of this feature.