6.1.2 Overview: Bayes' Rule

As discussed in Section 5.1.2, the Bayesian formula for speech recognition can be given as:
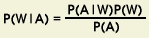 where:
where:
- P(A|W): acoustic model (hidden Markov models, mixture of
Guassians)
- P(W): language model (statistical, N-grams, finite state
networks)
- P(A): acoustic (ignore during maximization)
The objective of the recognizer is to minimize the word error rate by
maximizing P(W|A). We approach this first by maximizing P(A|W)
during training.
In this tutorial, we focus on the development of the language model,
P(W) . The language model predicts a set of next words. This
prediction can be based on knowledge of a finite number of previous words
(N-grams) or computed from a
probable path through a finite state network (network decoding). Either
method reduces the search space, a critical need for recognizer
performance.
|
|







