

State-of-the-art speech recognition systems have achieved low error rates on
medium complexity tasks such as Wall Street Journal (WSJ) which involve clean
data. However, the performance of these systems rapidly degrades as the
background noise level increases. With the growing popularity of
low-bandwidth miniature communication devices such as cell phones, palm
computers, and smart pagers, a much greater demand is being created for robust
voice interfaces. Speech recognition systems are now required to perform at a
near-zero error rate under various noise conditions. Further, since many of
these portable devices use lossy compression to conserve bandwidth, speech
recognition system performance must also not degrade when subjected to
compression, packet loss, and other common wireless communication system
artifacts. Speech coding, for example, is known to have a negative effect on
the accuracy of speech recognition systems.
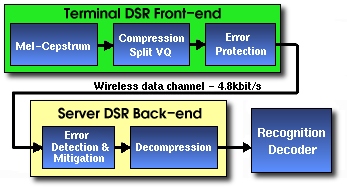
Aurora, a working group of ETSI, has been formed to address many of the issues involved in using speech recognition in mobile environments. Aurora's main task is the development of a distributed speech recognition (DSR) system standard that provides a client/server framework for human-computer interaction. In this framework, the client side performs the speech collection and signal processing (feature extraction) using software and hardware collectively termed as a front end. The processed data is transmitted to the server for recognition and subsequent processing. The exact form and function of the front end is a design factor in the overall DSR structure. Our collaboration with ETSI focuses on evaluating the performance of different front ends on the WSJ task for a variety of impairments:
|
