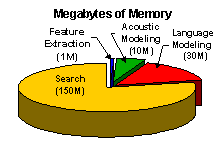
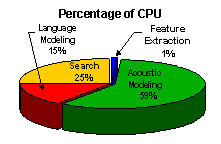
•
Typical LVCSR systems have about 10M free parameters, which makes
training a challenge.
•
Large
speech databases are required (several hundred hours of speech).
•
Tying, smoothing, and interpolation are required.