SWITCHBOARD is a corpus of spontaneous conversations which addresses
the growing need for large multi-speaker databases of telephone
bandwidth speech. The corpus contains 2430 conversations averaging 6
minutes in length; in other words, over 240 hours of recorded speech,
and about 3 million words of text, spoken by over 500 speakers of both
sexes from every major dialect of American English.
Project Goals
-
manually creating a new segmentation of the training database
that consists of utterances typically 10 seconds in duration
which are excised at significant pause boundaries and/or turn
boundaries
-
manually correcting the orthographic transcriptions for the
training database (the test database was already corrected at
WS'97 by the PI)
-
automatically creating a new set of word alignments by
performing supervised training on the new segmentations using
our best phone-based recognizer, and manually review these
word alignments for accuracy
-
manually creating a new test set segmentation that is
consistent with the training database; recalibrating the
improvement in performance achieved by syllable-sized acoustic
models
-
performing an error analysis to determine the dominant error
modalities of these systems.
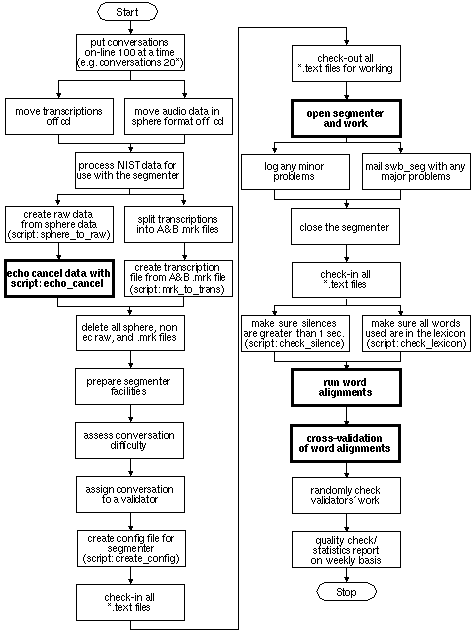
Plan
Our plan for resegmenting the database consists of a six step
process:
-
echo cancel the data
-
adjust utterance boundaries
-
correct the orthographic transcription of the new utterance
-
readjust boundaries if necessary
-
perform supervised recognition on the new utterances to get a
time-aligned transcription
-
review the word boundaries for gross errors
We are using the following CDs in this project:
-
"Switchboard-1 Transcriptions: Intermediate Version," August, 1997
-
"Switchboard-1 Telephone Speech Corpus: Release 2," August, 1997
An overview of the transcription process is given below: