6.3.1 N-Gram Modeling: Overview

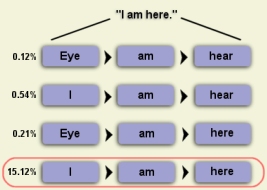
Consider the sequence of words, "I am here." The probability of this
word sequence can be estimated by measuring its occurrance in a set
of training data. To calculate this probability, we need to compute
both the number of times "am" is preceded by "I" and the number of
times "here" is preceded by "I am."
Clearly, estimating this probability for every possible word sequence
is not feasible. A practical approach is to assume this probability
depends only on an equivalence class. For example, group all nouns in
an equivalence class.
We can simplify this further by considering the following cases:
- Unigram: one word sequence
- Bigram: two word sequence
- Trigram: three word sequence
- N-gram: n word sequence
|
|
|







