Although speech recognition has been a well studed field over the past few
decades, it can be difficult to find tutorials that offer clear and useful
insight into the actual process of running a task. This website aims to provide
resources for new researchers to begin working on speech recognition
experiments.
There are several different open-source speech recognisers available to the
public. ISIP, Carnegie Melon's Sphinx, and Cambridge's HTK are some of the most
popularly used systems. For our intents and purposes these tutorials focus on
using HTK since a fair amount of documentation exists and there are additional
resources available should someone running these tutorials have problems.
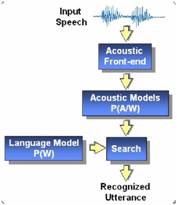
As the figure to the right shows, speech recognition can be broken down into a
few key processes. In these tutorials we'll focus on three key steps:
data preparation, acoustic modeling (i.e. training), and decoding (i.e.
obtainin results).
- Data Preparation:
Before doing anything, you must first ensure everything is in the correct
format and that you have all of the proper files for your experiment.
In this phase, you'll accomplish a few things including building a language
model for your task, converting your audio files into features to train
acoustic models, building a lexicon (i.e. reducing your
dictionary to a list of used words), generating lists of monophones or
triphones that exist in your data, and creating transcription files that are
needed to both train acoustic models and also later for decoding your results.
It's worth noting that the acoustic features mentioned above are most often
vectors of Mel Frequency Cepstral Coefficients (MFCC's).
- Acoustic Modeling / Training:
Once we have everything in the right format, we can begin to train our
acoustic models. The most common graphical structure for these are Hidden
Markov Models (HMM's). To train these acoustic models we use a multivariate
Gaussian distribution where each variable is represented by one of the
MFCC features. HTK uses the Baum-Welch algorithm (i.e. similar to the EM
algorithm) to estimate and maximize the means and covariances of the
models. Typically researchers expand these distributions to incorporate
Gaussian mixture models as well.
If you're not comfortable with some of this terminology, Lawrence Rabiner
has written a very useful explanation in A Tutorial on Hidden Markov
Models and Selected Applications in Speech Recognition.
- Decoding:
After we've finished training our HMM acoustic models, we use them to generate
a set of transcriptions for our testing data. We compare the generated results
to the actual transcriptions to determine the word error rate (WER) of the
system.