

|
Introduction
This work investigated peformance on several baseline algorithms - neural
networks(NN), random forests (RF), K nearest neighbors (KNN), and GMMs - as well as
three variational inference algorithms for Dirichlet process mixtures (DPMs)
- accelerated variational Dirichlet process mixtures (AVDPM), collapsed
variational stick breaking (CVSB, and collapsed Dirichlet priors (CDP).
Three corpora are used in this work - TIMIT, CALLHOME English (CH-E), and CALLHOME Mandarin (CH-M). Each corpora is partitioned into training, validation, and evaluation sets. Each algorithm is tuned such that optimal parameters are found for each model by minimizing the misclassification error on that set (validation error). The tuning results for each algorithm are shown below. Final misclassification error rates were found for all algorithms using the evaluation sets from each corpora and shown in Table 1. Finally, the amount of training time required for AVDPM, CVSB, and CDP were also measured and shown below. For additional discussion and more detailed analysis of these results, please read the papers in the Publications section of this website. 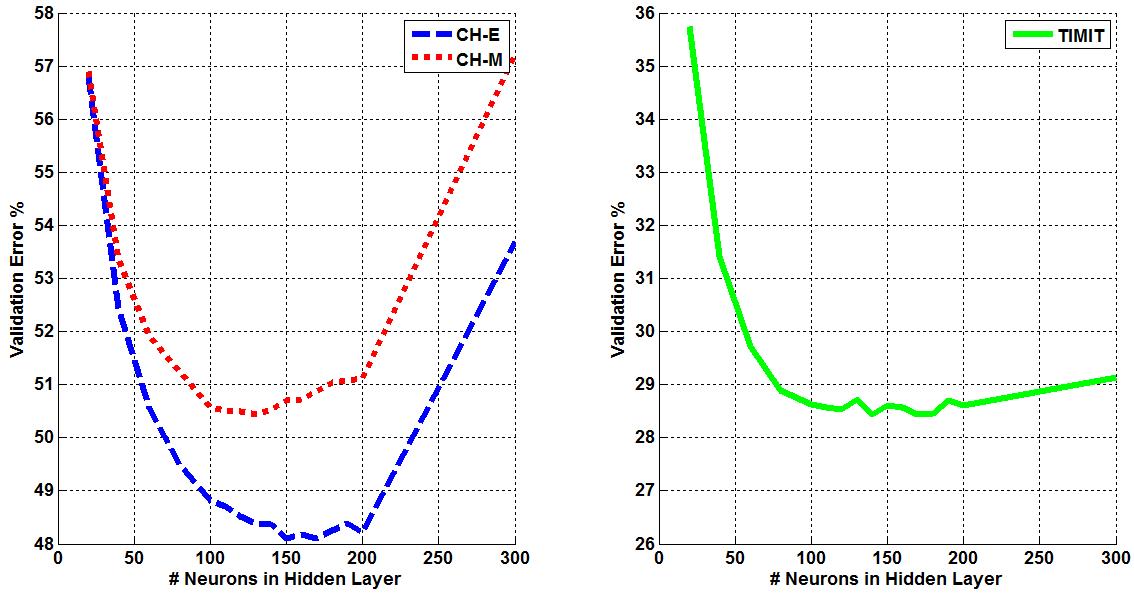 Figure 1: The average misclassification error from 10 iterations of the single hidden layer neural network model. The number of neurons in the hidden layer is swept from 20 to 300. 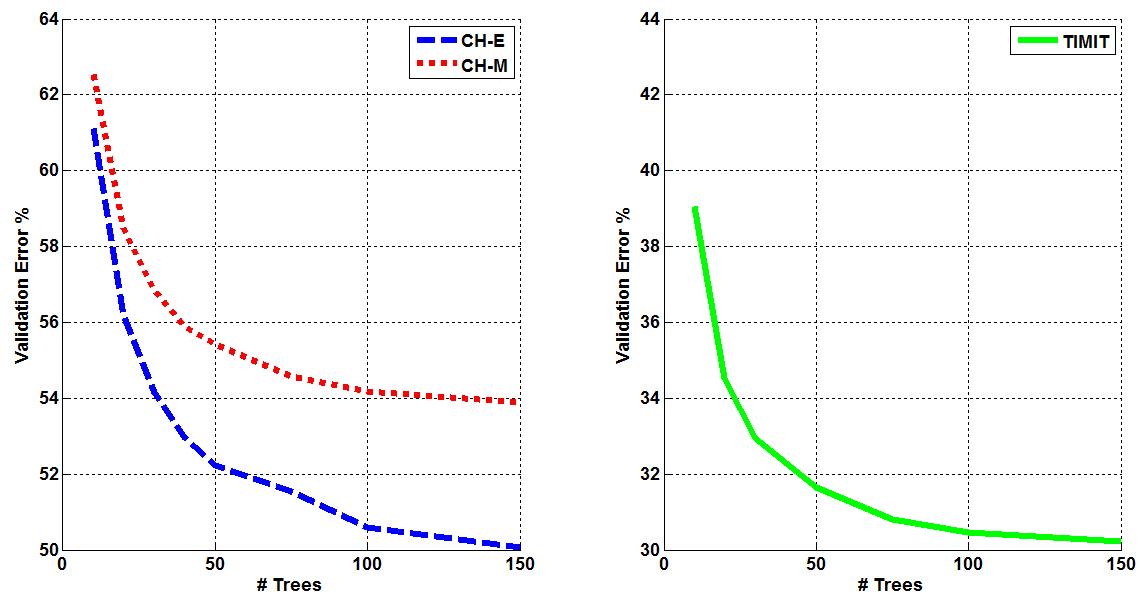 Figure 2: The average misclassification error from 5 iterations of the random forest algorithm as the number of trees in the ensemble is swept from 10 to 150. 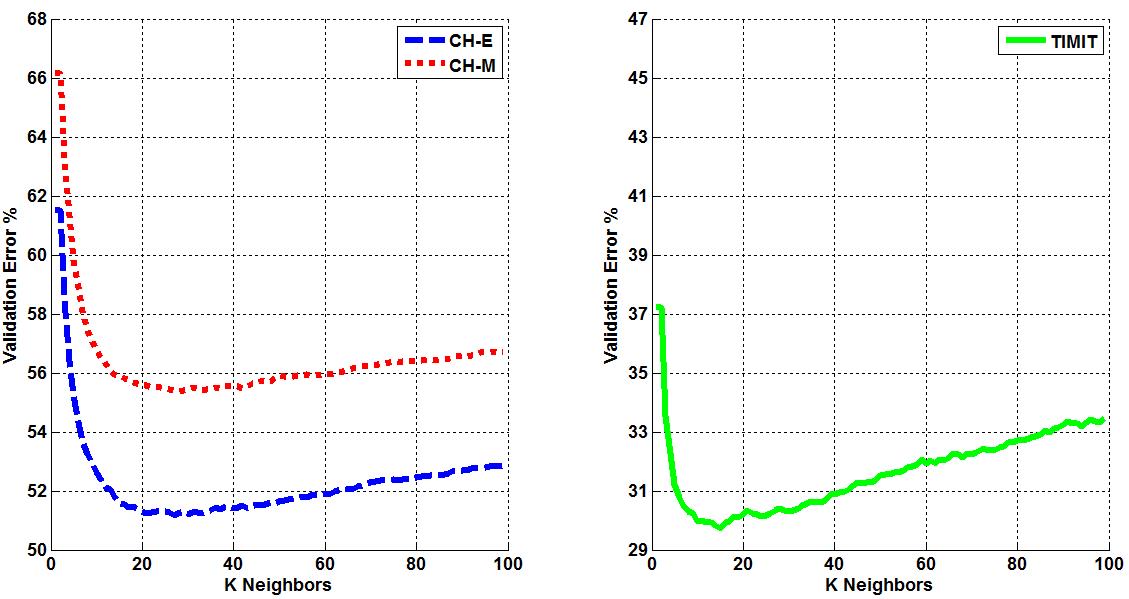 Figure 3: The misclassification error for KNN as K is swept from 1 to 99 nearest neighbors. 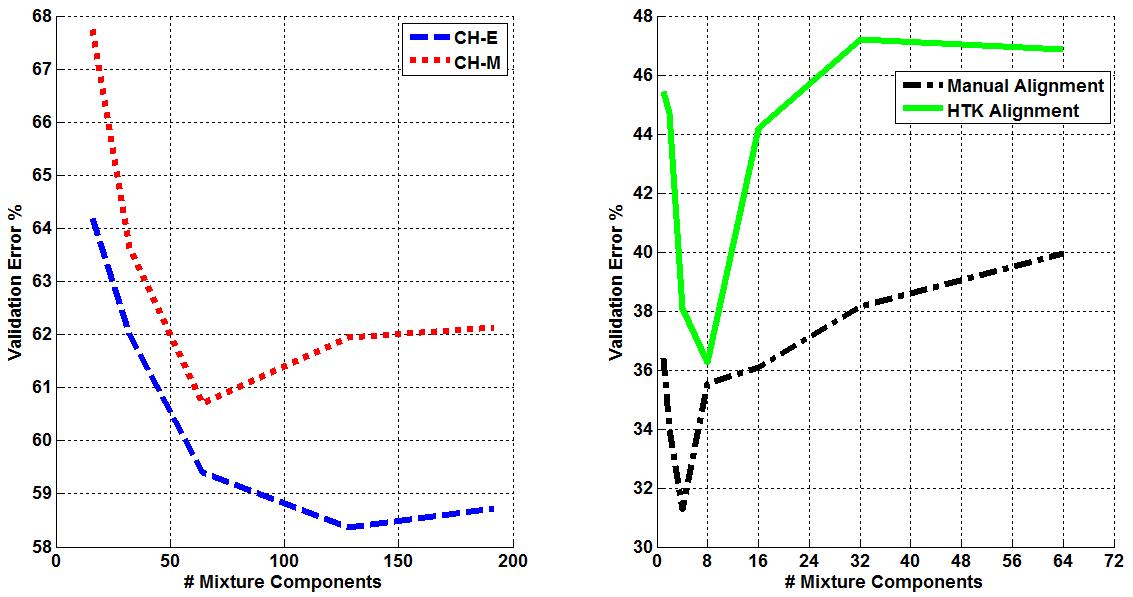 Figure 4: The best misclassification error from 10 iterations of a GMM as the number of mixture components is swept from 1 to 64 for TIMIT’s validation set and 16 to 192 for CH-E and CH-M. Results are shown for both manual and automatically generated phoneme alignments for TIMIT. 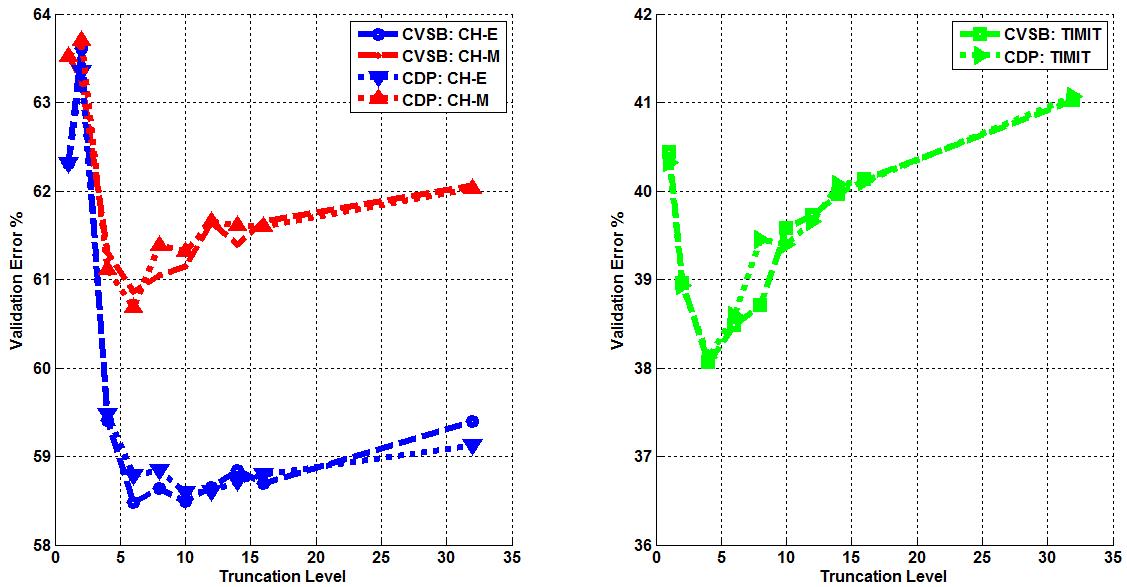 Figure 5: The misclassification error rates for CVSB and CDP are shown as the truncation level is swept for TIMIT, CH-E, and CH-M. 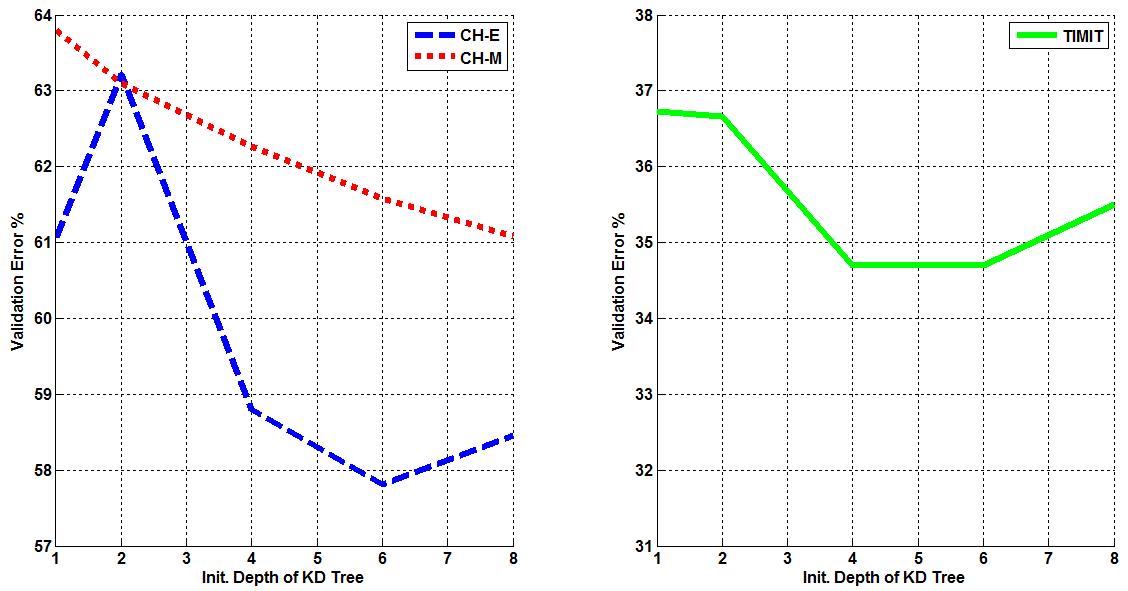 Figure 6: The misclassification error rates are shown as the initial depth of the KD tree is swept for TIMIT, CH-E, and CH-M. 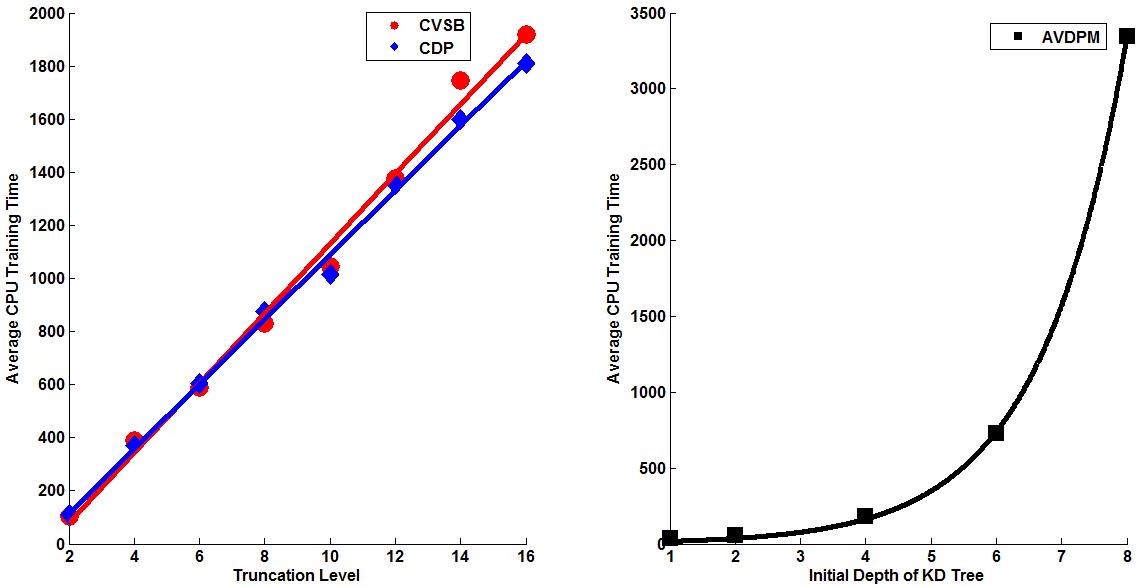 Figure 7: The average amount of CPU training time across 10 iterations for the TIMIT corpus as the truncation level and KD tree depth are varied for CVSB, CDP and AVDPM are shown. 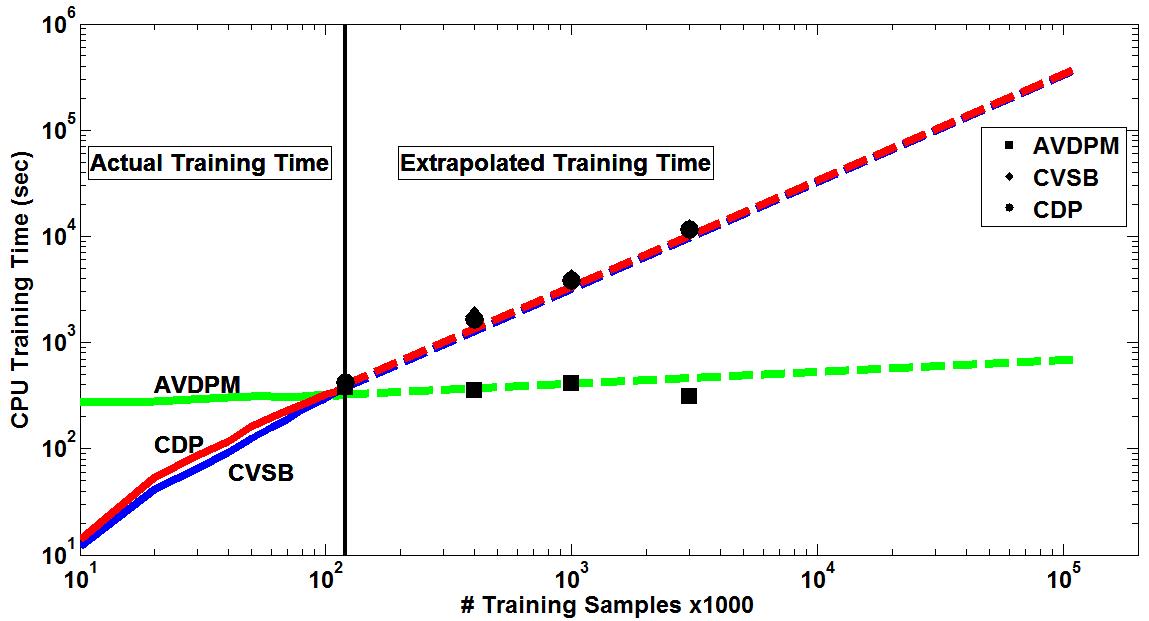 Figure 8: The average amounts of CPU training time vs. the number of training samples across 200 iterations at optimal operating points on the TMIIT Corpus are shown. Trends are extrapolated to show how AVDPM, CVSB, and CDP would perform on much larger corpora such as Fisher. The average amount of CPU training time across 10 iterations for the TIMIT Corpus as the truncation level and KD tree depth are varied for CVSB, CDP and AVDPM are shown. The points represent additional extrapolated results. 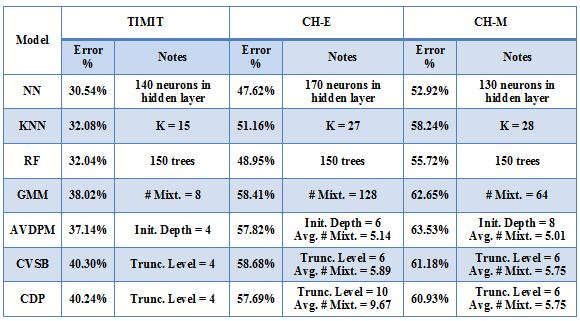 Table 1: A comparison of misclassification error and number of mixture components for the evaluation sets of the TIMIT, CH E, and CH M corpora using automatically generated alignments. |