SHARING TAILS OF TREES
- Assume a bigram language model.
- A linear tail in a lexical tree is defined as a subpath
ending in a leaf node and going through states with a unique
successor (also called a single-word subpath).
- LM factorization pushes forward the LM probability to the last
arc of the linear tail.
- We can optimize a tree to take advantage of shared-tail optimization.
Consider this tree before optimization:
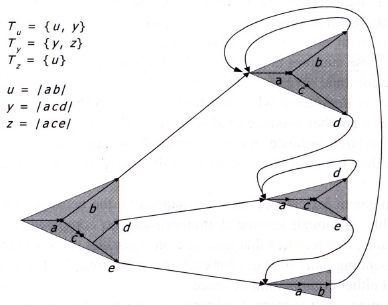
and this tree after shared-tail optimization:

- What are the advantages of this approach?