LINEAR REGRESSION
- We can simpify the previous equation by
imposing a central difference type formulation of the problem, as
shown below:
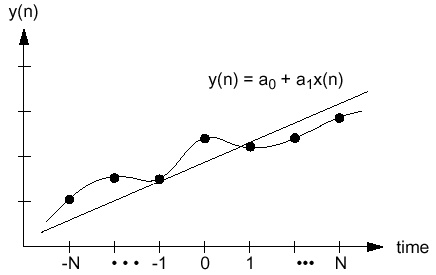 The x-axis is relabeled in terms of
equispaced sample indices, and centered about zero.
The x-axis is relabeled in terms of
equispaced sample indices, and centered about zero.
- This simplifies the calculation to:
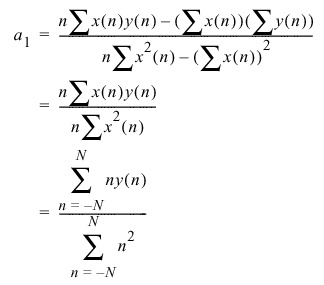
- This equation is the form we desire, and is extremely efficient
to compute. The denominator can be precomputed, and the integer
multiplications are easily implemented even in fixed-point
DSPs.
- Obviously, this approach can be extended to higher order
derivatives. However, historically, second derivatives in speech
recognition have been computed by applying two first-order derivatives
in succession.
- Further, the order of regression used, N, is most
commonly set to 2, which means a five-frame sequence of features is
required to compute the first-order derivative.