MULTIPLE COPIES OF PRONUNCIATION TREES
- A simple lexical tree is sufficient if no language model is used.
- For higher-order N-gram models, the linguistic state cannot be
determined locally. History plays an important role. For example,
for bigrams, a tree copy is required for each predecessor word.
- Efficient pruning can eliminate most of the unnecessary tree copies.
- To deal with tree copies, you can create redundant trees for each
word context. However, this is expensive.
- Many of the active state hypotheses correspond to the same
redundant unigram state because the language model probability
cannot be applied until the next word has been observed.
- A successor tree approach can be used to eliminate this redundancy:
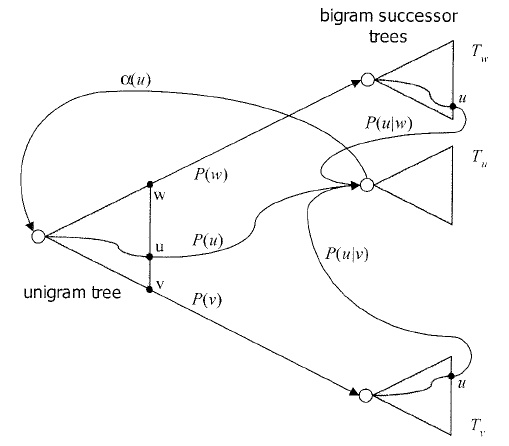
- However, for backoff language models, this isn't as efficient as
it might seem (unless aggressive pruning is used to allow only
a small subset of words to follow a given word).