HMM LIMITATIONS: CONDITIONAL INDEPENDENCE
Recall our basic acoustic model topology:
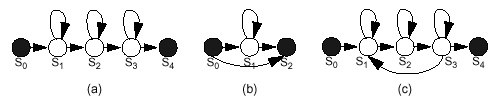 It can be argued that HMMs do not provide a realistic model
for the temporal structure of speech:
It can be argued that HMMs do not provide a realistic model
for the temporal structure of speech:
- Observation probabilities for each frame (or state) are independent
of previous or future frames (conditional independence). Is this
a realistic model?
- The probability of staying in a state decays exponentially.
What can we do to overcome these deficiencies?