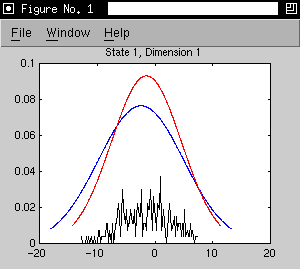
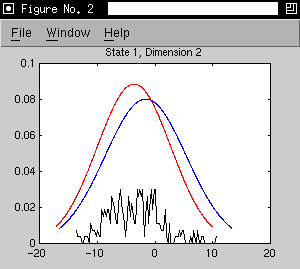
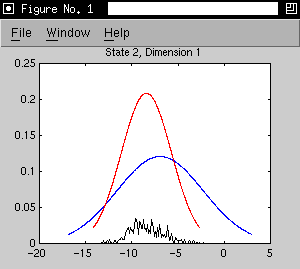
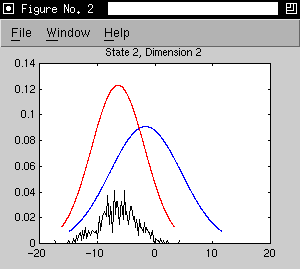
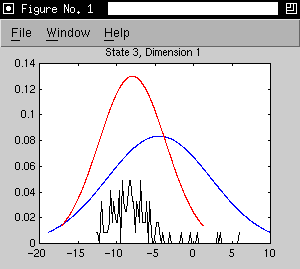
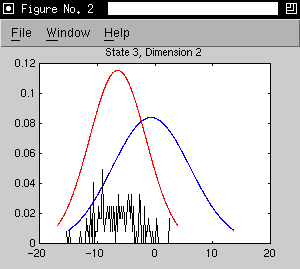
- initial model is the three states of the 's' phone model trained on
Alphadigit data
- adaptation data is extracted from forced alignments of 21 utterances by
one speaker. (267 adaptation observations for state 1, 485 for state
2 and 122 for state 3)
- as an example, we consider a 2D model with the first two cepstral
coefficients