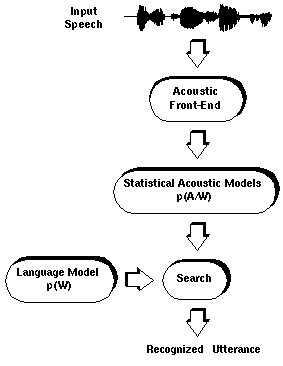
-
The main problem in Speech recognition is to choose the most
probable word sequence from all the words that could have been
possibly generated.
-
If
W=w1,w2,w3,...,wN,
is the sequence of words spoken and if A is the acoustic
evidence presented , then the recognition system must choose a
word string W' that maximizes the probability that W
was spoken given that A was observed
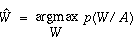
-
The Bayesian approach is used to the above posteriori
probability since there may be infinite number of word
sequences for a given language
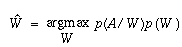 In the above equation p(A/W) is provided by acoustic
model and p(W) is given by the language model
In the above equation p(A/W) is provided by acoustic
model and p(W) is given by the language model
-
The process of combining these two probability scores and
finding the maximum after sorting through all possible
combinations is called Search or Decoding